
I'm a Senior Applied Scientist at Microsoft in the Outlook organization, where I build and study agentic systems for email work, with an emphasis on delegation and agent's proactivity.
I hold a Ph.D. in Human-Computer Interaction from Carnegie Mellon University (CMU). My training is grounded in cognitive science and behavioral methods, with prior work on the scientific study of human-AI co-creativity and ML/LLM-powered interactive systems. Across projects, I pair empirical research (controlled experiments, mixed-method studies, behavioral measurement) with system-building to translate findings into product direction and evaluation frameworks.
Previously, I worked in PowerPoint AI on multimodal agentic systems for presentation generation/editing and slide-native evaluation.
I've collaborated with the Toyota Research Institute, the
Allen Institute for AI (AI2), and MIT to design and deploy AI-driven systems with real-world
impact.
At AI2, I worked on Semantic Scholar's improved paper-alert
emails, led engagement analyses that guided their launch, and published
multiple research papers with AI2 collaborators.
Additionally, I partnered
with
Conservation X Labs
to develop team-formation algorithms for global open-innovation
contests offering over $2 million in prize funding.
My research is now required reading at Virginia Tech and CMU. I've received multiple awards, including a Best Paper Award at ACM CHI (2024), a Best Paper Honorable Mention Award at ACM CHI (2025), and a Google Cloud Innovator Award (2021).
Publications
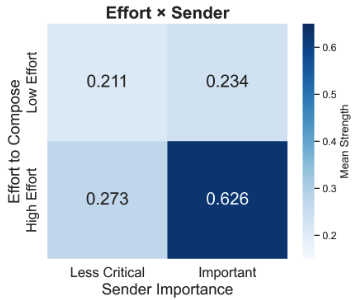 Pre-print
Pre-print
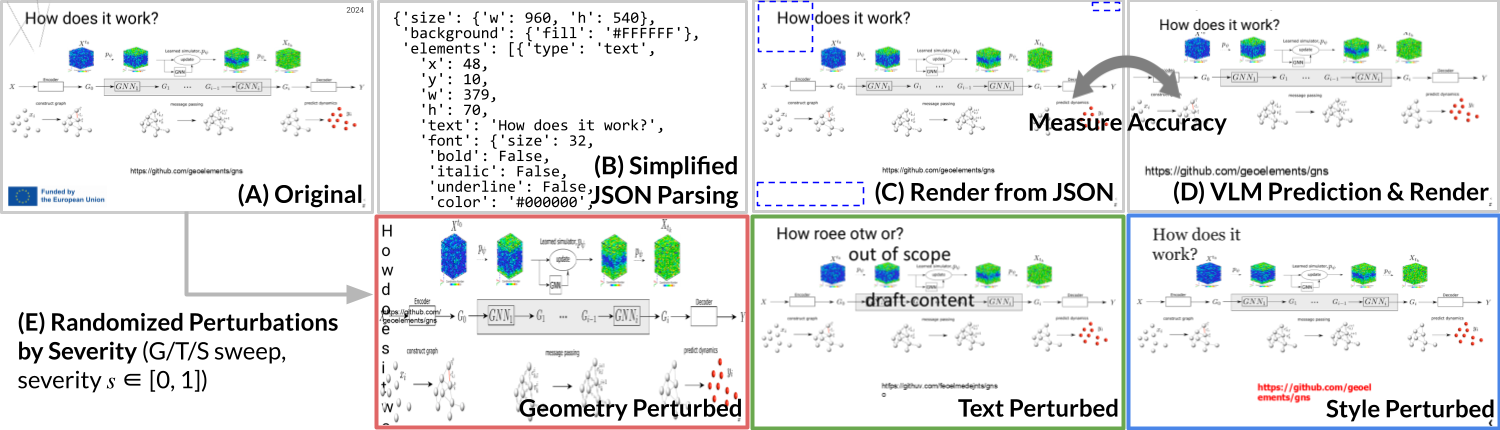 NeurIPS 2025
NeurIPS 2025
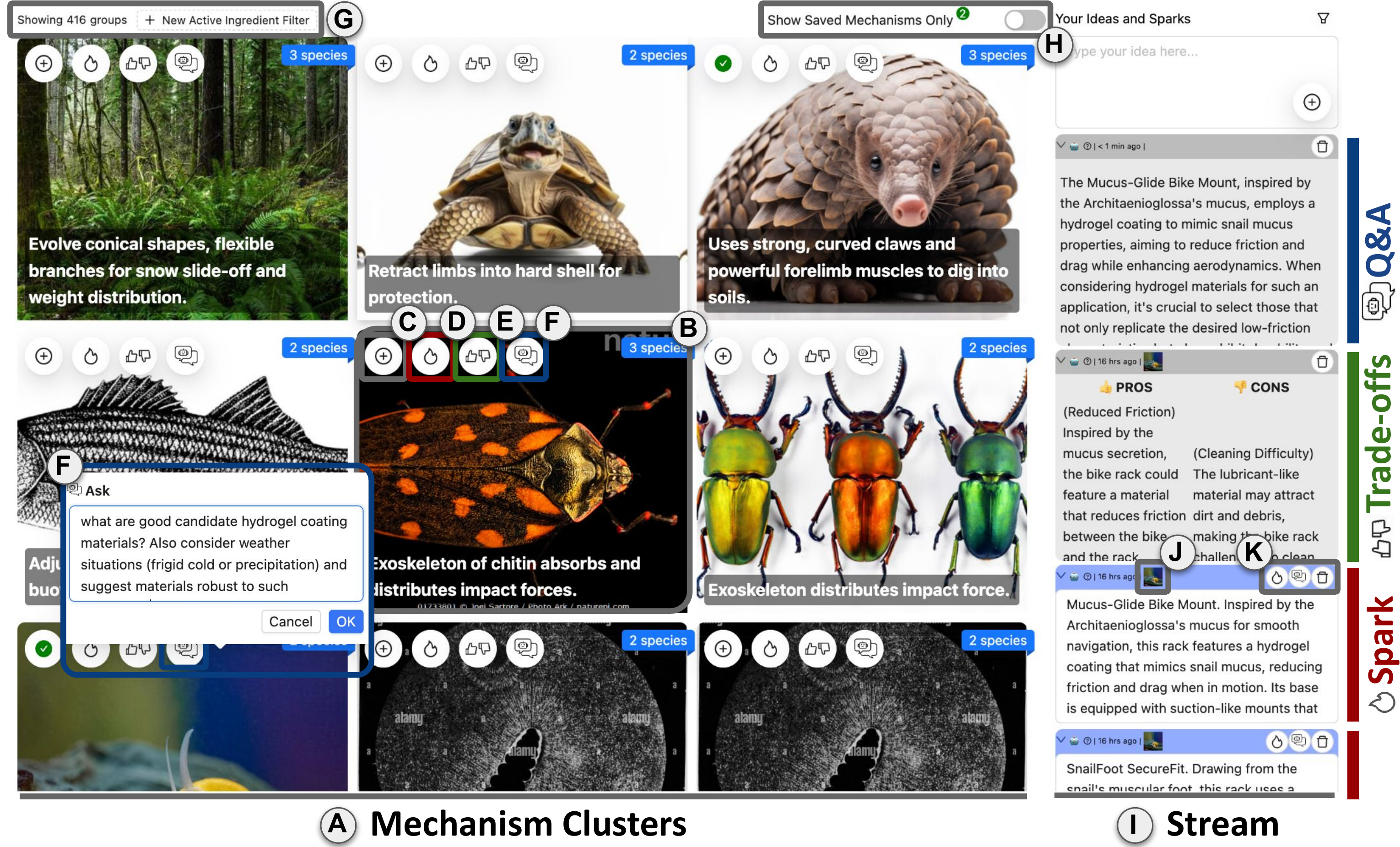 🥇 CHI 2025
🥇 CHI 2025
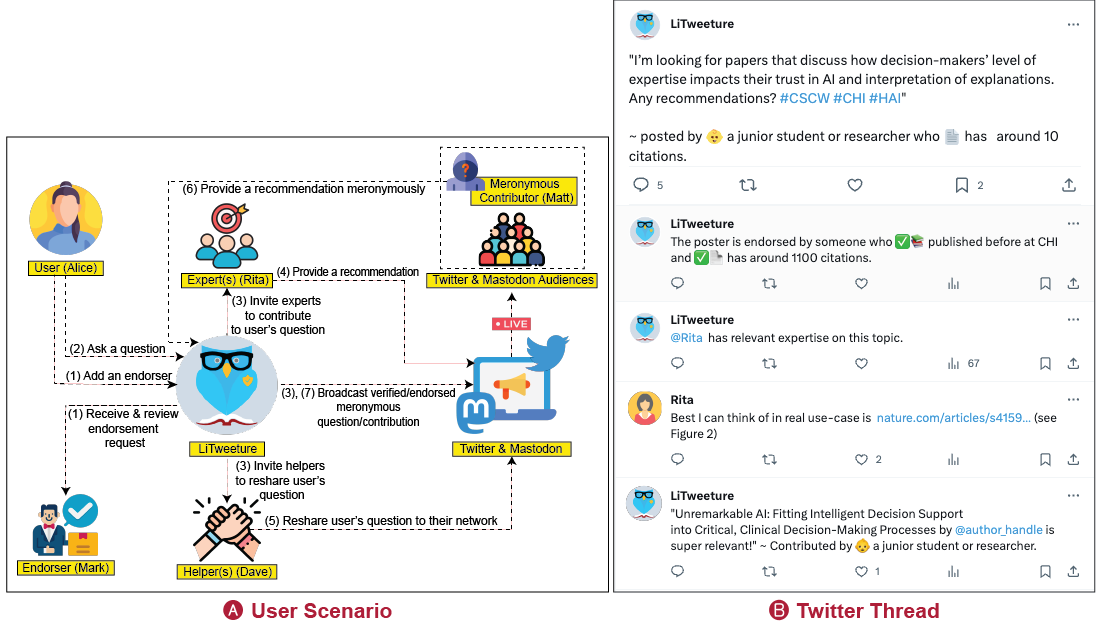 🏆 CHI 2024
🏆 CHI 2024
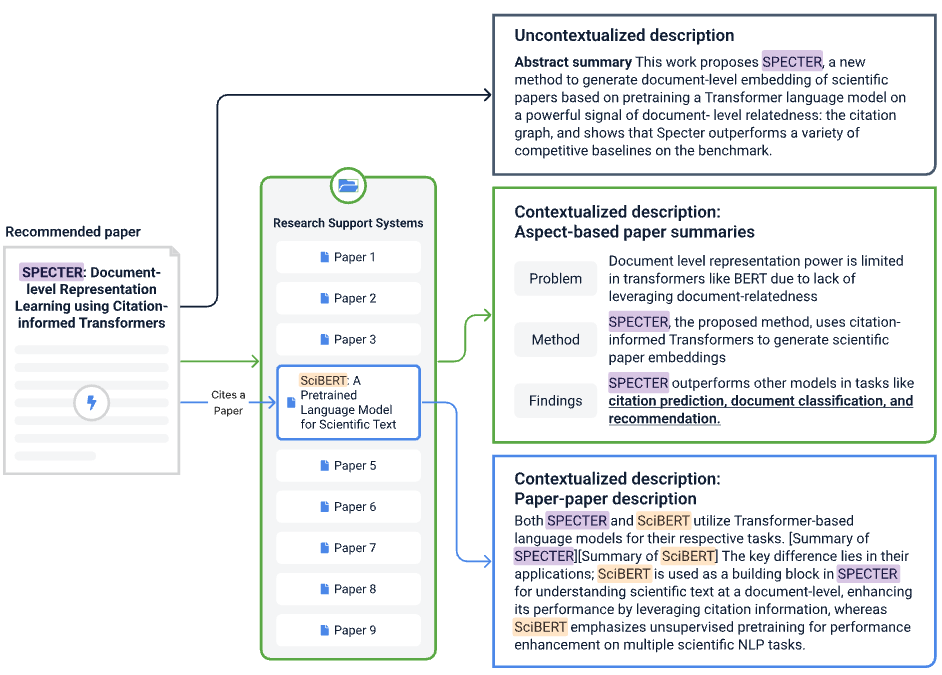 CHI 2024
CHI 2024
 CACM 2024
CACM 2024
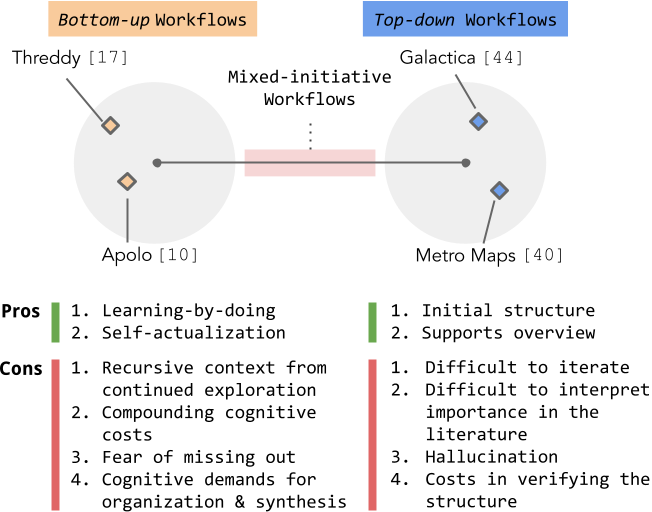 UIST 2023
UIST 2023
A demo video of Synergi is available here.
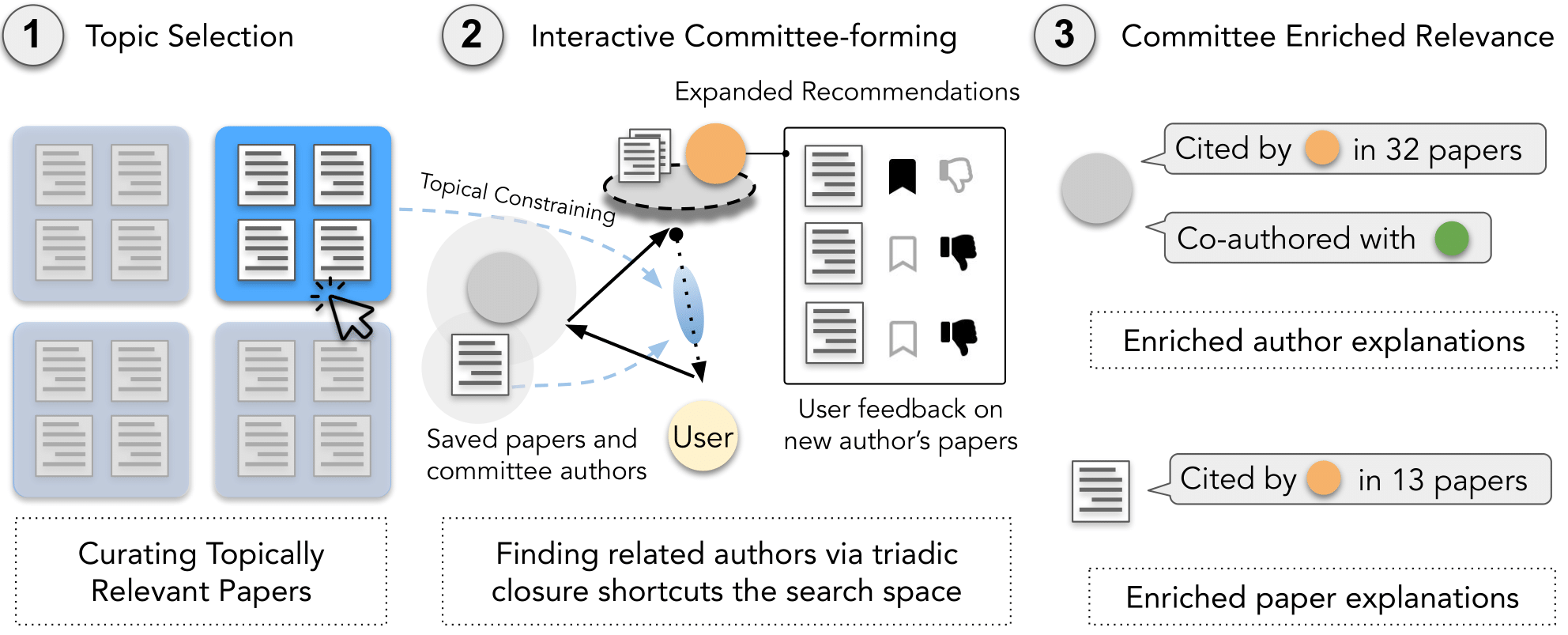 CHI 2023
CHI 2023
A demo video of ComLittee is available here.
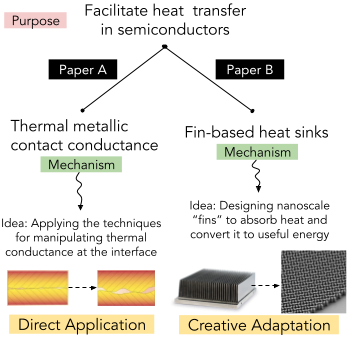 TOCHI 2022
TOCHI 2022
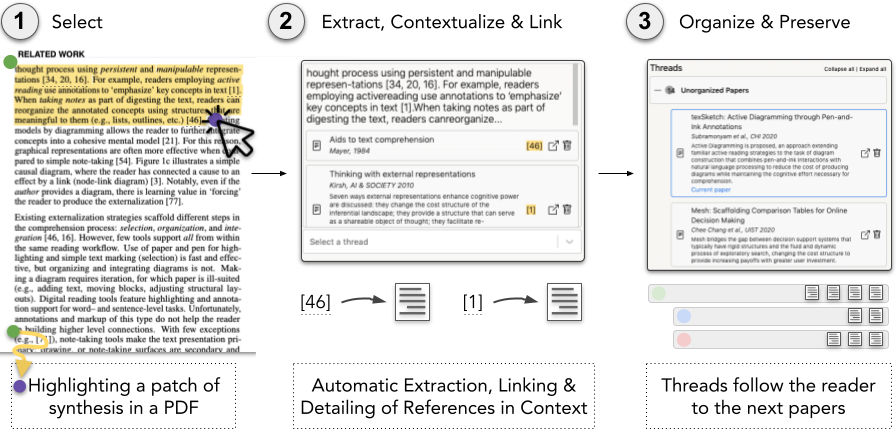 UIST 2022
UIST 2022
 CHI 2022
CHI 2022
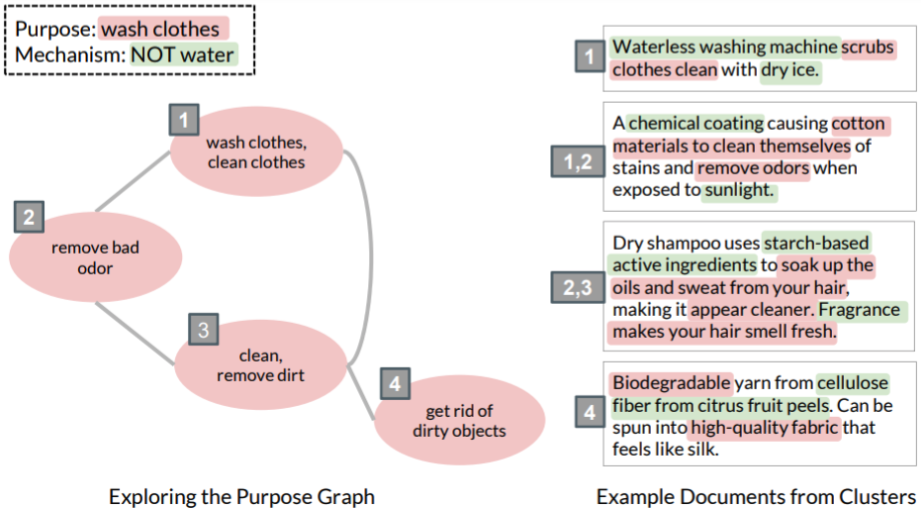 CHI 2022
CHI 2022
 CHI 2018
CHI 2018
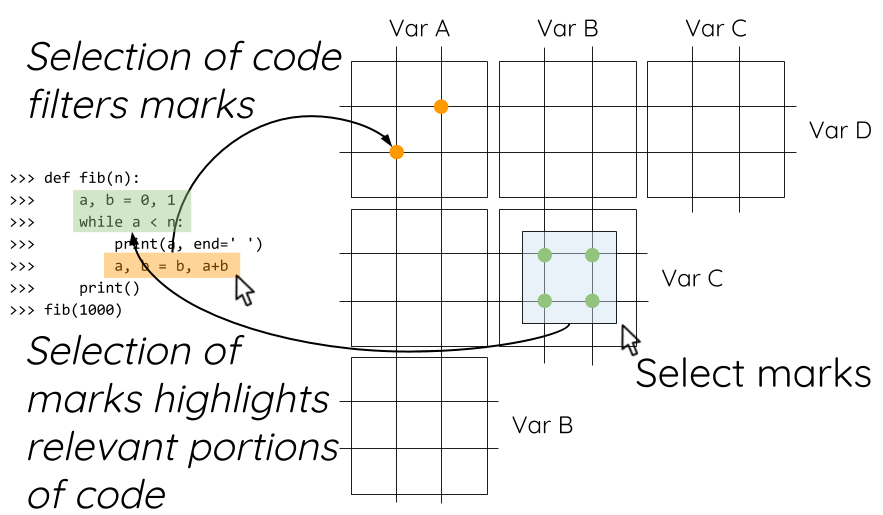 UIST 2017
UIST 2017
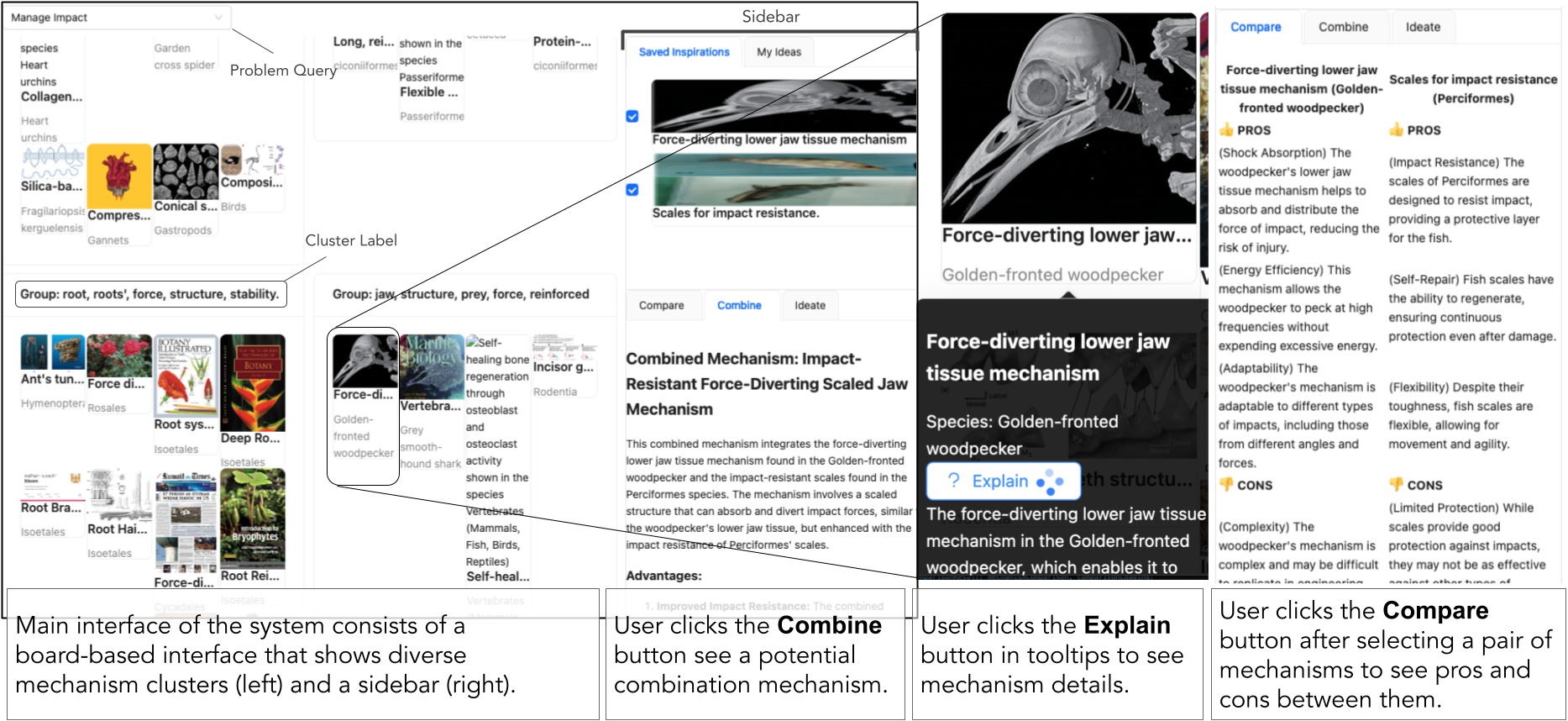 NeurIPS 2023
NeurIPS 2023
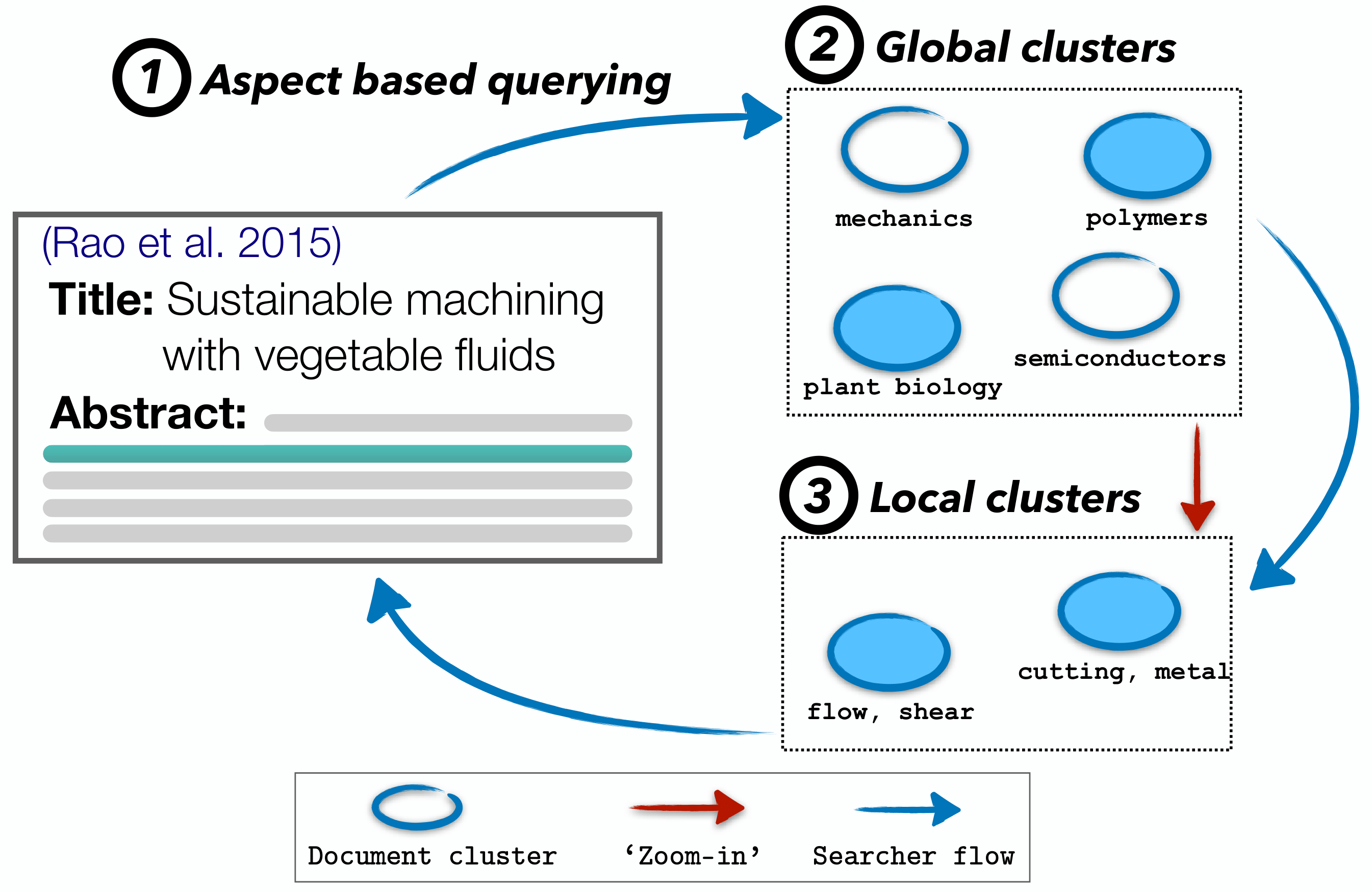 NAACL 2022
NAACL 2022
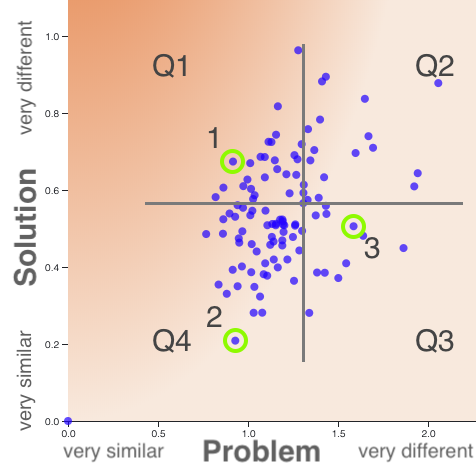 CI 2019
CI 2019
 SIGPLAN 2018
SIGPLAN 2018